
原文链接
所谓爬虫用我自己的理解就是:用代码去取代人力进行一些反复的鼠标键盘点击事件动作而已(说高大上一点就是:数据整理)
提前科普一下
可能只是我不知道而已 音乐的格式
WAV格式
MP3格式
m4a格式 (qq音乐格式 这里表示我只知道MP3 WAV)
WMA格式 (以下表示都不知道是什么格式)
OGG格式
APE格式
ACC格式
其实思路很简单
- 搜索歌手名称
- 对搜索歌曲名称以及对应数据进行整理
- 点击歌曲进入以后参数查找
- 找到参数拼接URL 将参数带进去得到响应数据 将其下载整理
比较难点就是接口稍微有点不好找第一步:搜索
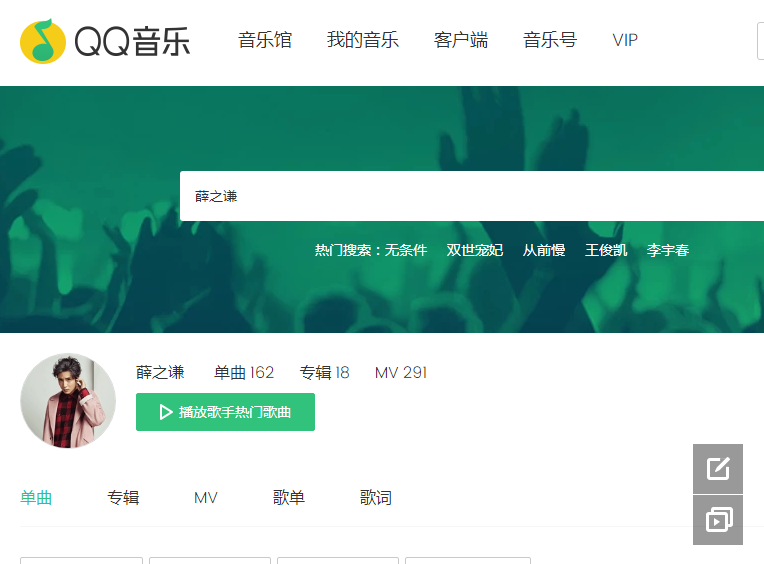
第二步:打开浏览器
点击NetWork 监控浏览器发送的请求 找到搜索结果响应的数据
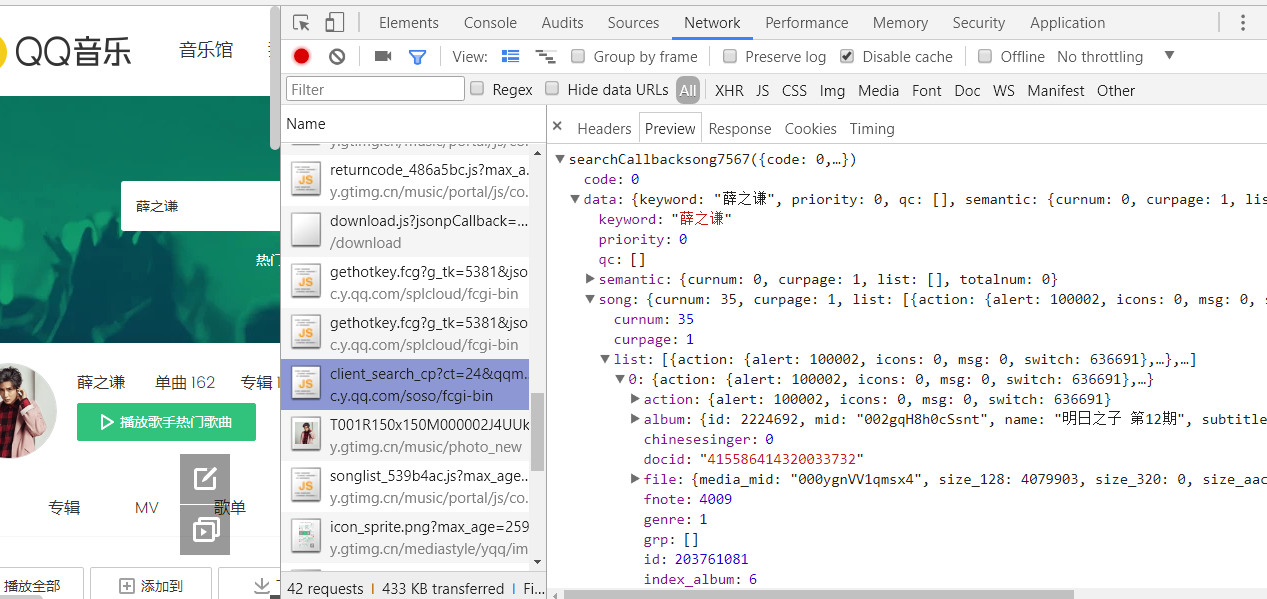
第三步:点击headers
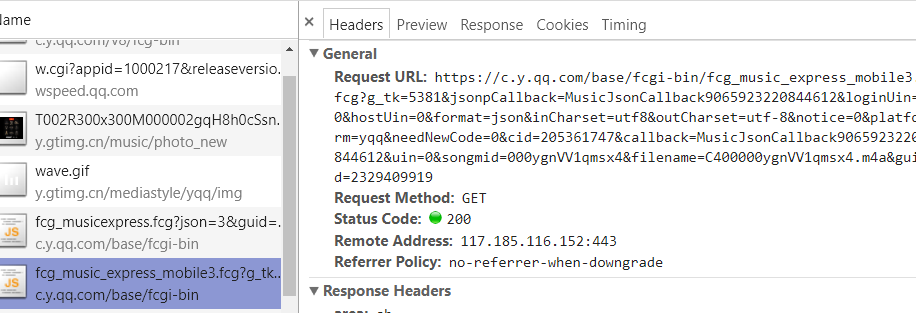
记录下此时的Request URL
这里的url是我们获取上述数据,使用python模拟浏览器发送请求的url

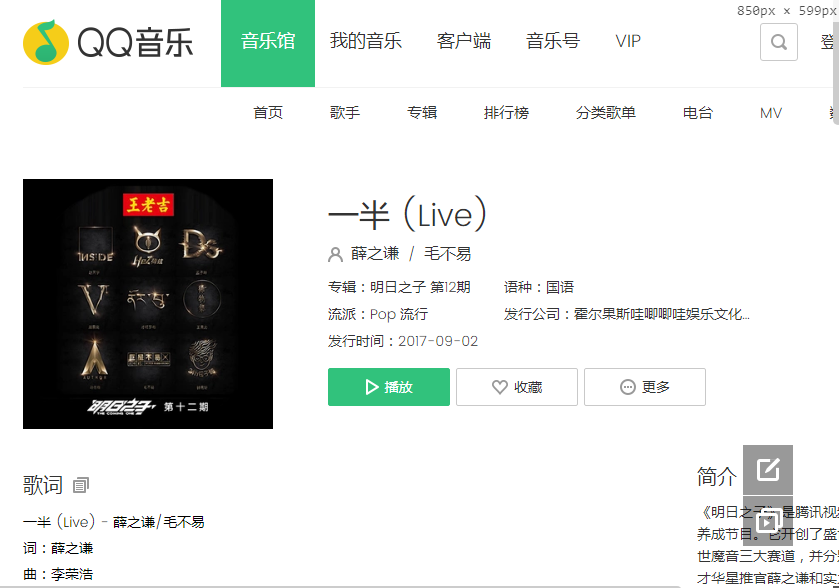
第四步:点击其中一首歌 进去详情页面
到这一步我们还没有获取到歌曲文件 继续点击播放
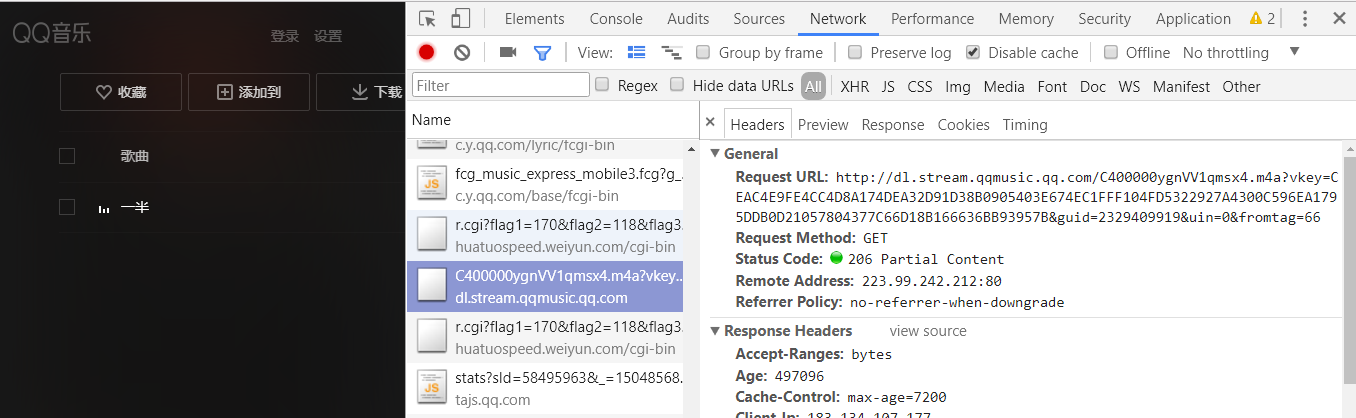
第五步:单曲详情页
到这里我们继续点击播放按钮 并且实时监控Network 找到.m4a的文件请求 该文件就是我们想要下载的文件
第六步:查找获取歌曲所需要的数据
在进行第五步的时候 我们发现 url后面所带有的参数 每首歌曲都是不一样的
所以在发送这个请求之前 应该会有数据返回来告诉浏览器发送的数据内容
如下接口是返回数据内容 这里稍微有点乱
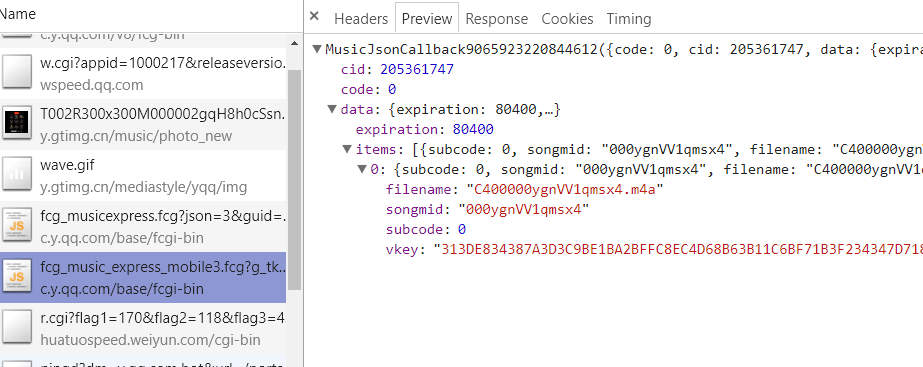
第七步:记录下此时的Request URL 获取歌曲信息
注意:在进行这一步的时候 发送所需的数据是从搜索结果里面获取的
搜索结果URL
page 表示页数 默认搜索到的是第一页 word 表示搜索歌手
获取M4A文件之前获取参数的URL
songmids mids 应该表示歌曲的id
获取M4A文件的URL
‘http://dl.stream.qqmusic.qq.com/C400'+mids[n]+'.m4a?vkey='+vkey+'&guid=6612300644&uin=0&fromtag=66'
vkey mids 获取歌曲所需要的的数据
附上源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48import requests
import urllib
import json
def DownLoad(word,page=1):
res1 = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p='+page+'&n=20&w='+word)
#请求返回信息
jm1 = json.loads(res1.text.strip('callback()[]'))
#歌曲list
jm1 = jm1['data']['song']['list']
#提前声明一些list
mids = []
songmids = []
srcs = []
songnames = []
singers = []
#循环将每次请求所需数据进行push到相应list
for j in jm1:
try:
mids.append(j['media_mid'])
songmids.append(j['songmid'])
songnames.append(j['songname'])
singers.append(j['singer'][0]['name'])
except:
print('wrong')
#取到每首歌曲的信息 拼接对应url 将其push进去到相应的list
for n in range(0,len(mids)):
res2 = requests.get('https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?&jsonpCallback=MusicJsonCallback&cid=205361747&songmid='+songmids[n]+'&filename=C400'+mids[n]+'.m4a&guid=6612300644')
jm2 = json.loads(res2.text)
vkey = jm2['data']['items'][0]['vkey']
srcs.append('http://dl.stream.qqmusic.qq.com/C400'+mids[n]+'.m4a?vkey='+vkey+'&guid=6612300644&uin=0&fromtag=66')
print('For '+word+' Start download...')
x = len(srcs)
for m in range(0,x):
print(str(m)+'***** '+songnames[m]+' - '+singers[m]+'.m4a *****'+' Downloading...')
try:
print(srcs[m])
#根据URL循环下载文件 文件路径必须提前存在
urllib.request.urlretrieve(srcs[m],'E:/music/'+songnames[m]+' - '+singers[m]+'.m4a')
except:
x = x - 1
print('Download wrong~')
print('For ['+word+'] Download complete '+str(x)+'files !')
DownLoad('薛之谦',1)
